What language has the most in common with Vietnamese?
- 1. Introduction to WALS Online
- 2. Processing Data from WALS using computer
- 3. Calculating the Similarity Between Two Languages from WALS Data
- 4. Conclusion

Vietnamese, the beautiful and rich language of the Vietnamese people, is one of the languages with a long-standing tradition and history. With over a thousand years of development (starting from the original Viet-Muong language), Vietnamese has become a unique cultural symbol of the Vietnamese people. Its uniqueness lies not only in its melodic quality but also in its rich and flexible vocabulary, grammatical structures, and its ability to convey profound and nuanced meanings.
In this article, we will explore which language shares the most similarities with the mother tongue of over 90 million people worldwide.
1. Introduction to WALS Online
According to the website:
The World Atlas of Language Structures (WALS) is a large database of structural (phonological, grammatical, lexical) properties of languages gathered from descriptive materials (such as reference grammars) by a team of 55 authors.
WALS Online is a useful tool when you want to quickly search for the characteristics of a particular language, or look up languages that possess a specific feature (WALS has around 192 features) that you’re interested in. For example, here, I want to check feature 81A (Order of Subject, Object, and Verb), and the result returned from WALS will appear as shown below:
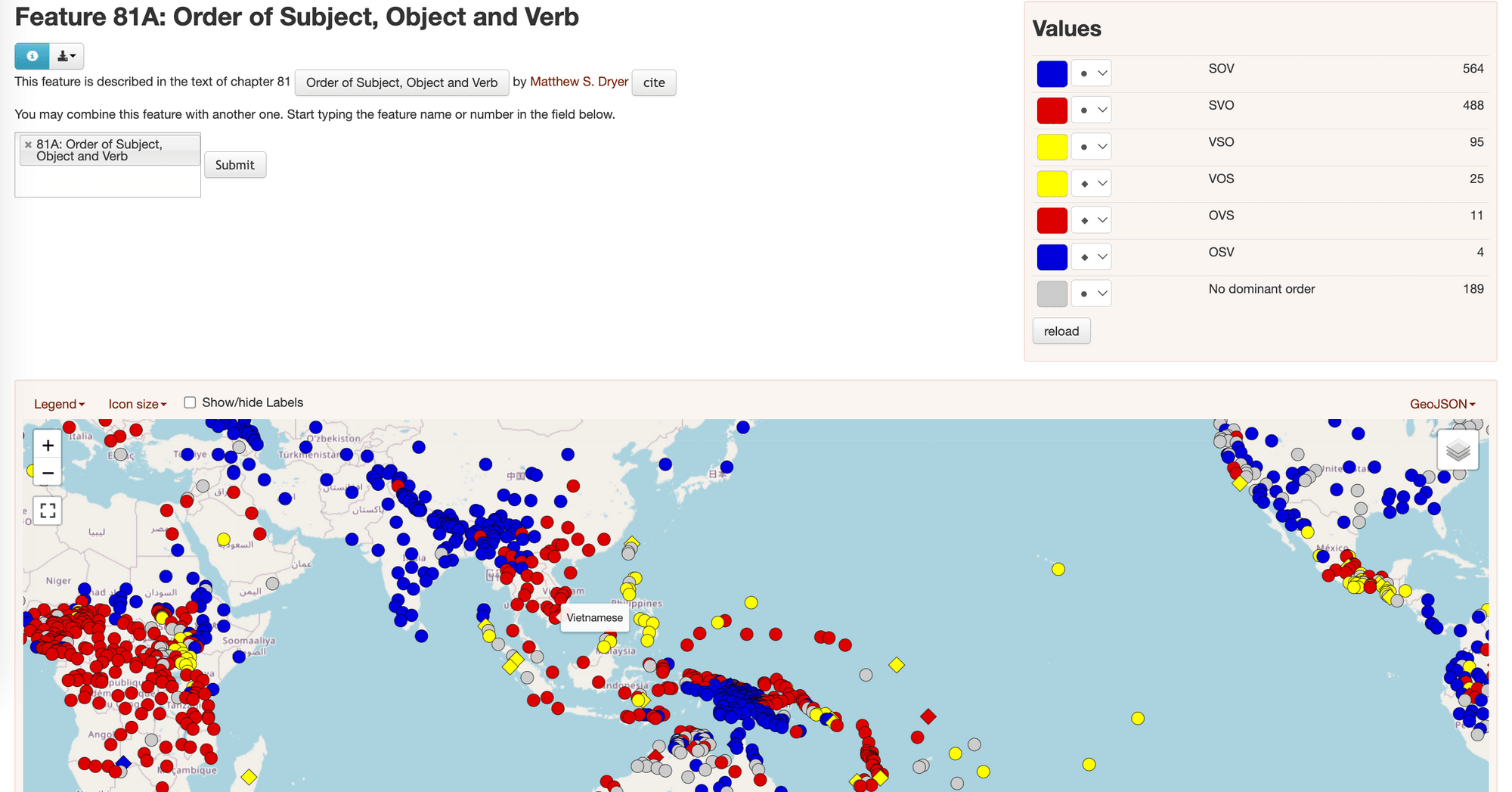
2. Processing Data from WALS using computer
Accessing information through the web interface is convenient and quick, but it is not sufficient for more complex processing needs. In such cases, we need to convert the data into a format that can be processed by a computer. WALS provides the data for free in CSV (Comma-separated values) format, but for easier processing, here I will use the data that has been converted into TSV (Tab-separated values) format, with the original data from 2018.
2.1. Working with Data from the Terminal
To perform calculations directly with data files, we can use the commands available in the terminal to process the data. Some common commands that can be used are:
| Command | Function |
|---|---|
| `grep` | Find matching patterns in a file |
| `wc` | Count words, lines, characters, and bytes |
| `cut` | Extract sections from lines in a file |
| `tr` | Replace, delete, or convert lowercase to uppercase, etc. |
| `sort` | Sort lines in a file |
| `uniq` | Count unique lines, remove duplicate lines, etc. |
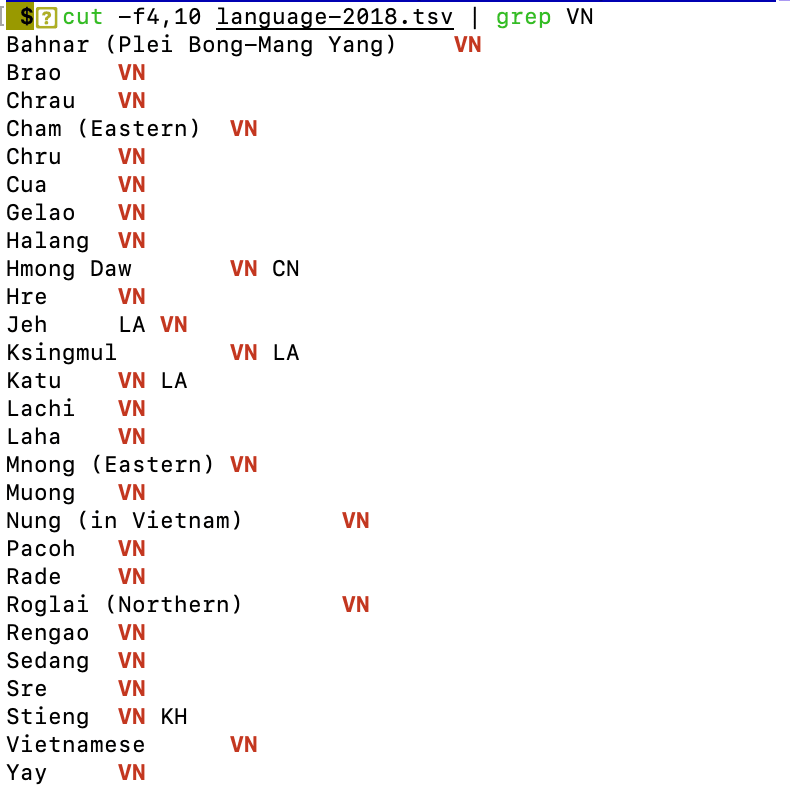
The commands above can be intelligently combined to retrieve the information you want. For example, here, I want to find out which languages are spoken in Vietnam and have information available on WALS. The command used will be:
cut -f4,10 language-2018.tsv | grep VN
3. Calculating the Similarity Between Two Languages from WALS Data
The main idea here is to write a Python script to estimate the similarity between two input languages, based on their WALS features.
The simplest approach would be: for each feature of the language, ignore the features that are not available for one or both languages, and add 1 to the score if the feature values are the same for both languages, and 0 if they are different. Dividing the score by the total number of features gives the Hamming similarity. The formula for calculating the Hamming similarity between two languages $s$ and $t$ based on the features $n$ is defined as \eqref{hamming-sim}:
\[\begin{equation}\label{hamming-sim} \begin{aligned} \text{HammingSim}(s, t) &= \frac{1}{n} \sum_{i=1}^{n} \delta(s_i, t_i) \\ \end{aligned} \end{equation}\]where $\delta(s_i, t_i)$ is the Kronecker delta function, which returns 1 if $s_i = t_i$ and 0 otherwise.
3.1. Finding the Languages with the Highest Similarity Score to a Target Language
Below is a script to calculate the languages with the highest Hamming similarity to a target language:
import csv
def wals_tsv_to_dict(tsv_file_path):
with open(tsv_file_path, 'r') as f:
reader = csv.DictReader(f, delimiter='\t')
wals_dict = {}
for row in reader:
wals_dict[row['wals_code']] = row
return wals_dict
def most_similar_language(wals_code, n=5):
sim_scores = []
wals_dict = wals_tsv_to_dict('language-2018.tsv')
target_lang_features = wals_dict[wals_code]
for code, features in wals_dict.items():
if code == wals_code:
continue
sim_score = 0
for feature, value in features.items():
if value == '' or target_lang_features[feature] == '':
continue
if value == target_lang_features[feature]:
sim_score += 1
sim_score /= len(features)
sim_scores.append((code, features['Name'] , sim_score))
sim_scores.sort(key=lambda x: x[2], reverse=True)
return sim_scores[:n]
3.2. Applying to Vietnamese
Running the above script with Vietnamese (vie) and some common languages worldwide such as English (eng), Chinese (mnd), and German (ger), we obtain the following results:

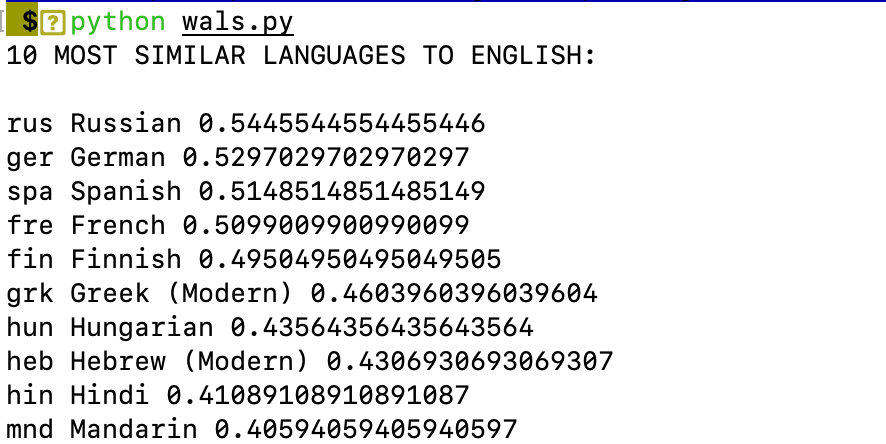


Top 10 Languages with the Highest Hamming Similarity to Vietnamese, English, Chinese, and German (from left to right, top to bottom).
From the above results, for Vietnamese, the language with the most similar features is Thai (tha), followed by Indonesian (ind), Hmong (hmo), and Chinese (mnd). Hmong is a language spoken in Vietnam and southern China, so it is understandable that it shares many similarities with Vietnamese. Similarly, Chinese, a major language with a significant influence on Vietnamese, shares many common features, as both countries have overlapping cultural and customs traits. One surprising language for me is Thai, with 112 features matching Vietnamese out of nearly 200 features. Some of the common features include:
- Located in the Eurasian continent (
Macroarea: Eurasia) - Complex tone system (
Tone: Complex tone system) — Vietnamese has 5 diacritics and 6 tones, while Thai has 4 diacritics and 5 tones - Morphology of words — little inflection (
Prefixing vs. Suffixing in Inflectional Morphology: Little affixation) - No grammatical gender (
Number of Genders: None) - Other features such as prepositions preceding noun phrases (
Order of Adposition and Noun Phrase: Prepositions), adjectives following nouns (Order of Adjective and Noun: Noun-Adjective), etc.
Below is the code to identify the matching features between two languages:
def get_match_features(lang1, lang2):
wals_dict = wals_tsv_to_dict('language-2018.tsv')
lang1_features = wals_dict[lang1]
lang2_features = wals_dict[lang2]
match_features = []
for feature, value in lang1_features.items():
if value == '' or lang2_features[feature] == '':
continue
if value == lang2_features[feature]:
match_features.append((feature, value))
return match_features
3.3. Extension
From the WALS dataset, we can perform other interesting tasks such as:
- For a genus (a smaller group within a larger linguistic family), find the centroid language within that language group. In other words, find the language that is most similar to the other languages in the group.
- Identify the most ‘unusual’ language — the language that is the least similar to the others. (Either within the entire WALS dataset or within a specific linguistic family or genus)
Our Vietnamese language belongs to the Austroasiatic language family, within the Viet-Muong genus, along with the Muong language.
4. Conclusion
Identifying languages with the most similarities to each other can enhance the effectiveness of solving other problems in NLP, such as cross-lingual transfer, low-resource machine translation, etc. In this article, we have explored WALS and applied its linguistic feature database to find the languages most similar to Vietnamese.
Thank you for reading. See you in the next article! 🤓